前一段时间学习了数据可视化谷歌趋势。
谷歌趋势允许把折线图上的数据按照日期和词条顺序以csv表格文件的形式下载下来。
但还是不如爬虫抓取数据来得快。
于是在Github找谷歌趋势的爬虫。
pytrends:https://github.com/GeneralMills/pytrends
首先该搭梯子的还是要搭梯子……
调用TrendReq().build_payload函数即可读取词条的热度趋势数据,在参数里面可以设置时间读取的时间范围。
谷歌趋势的热度数值范围是0~100。
当词条只有单个时,读取到的热度是相对于本词条最高热度的热度数值。
也可以把多个词条同时加入到词条数组里面(遗憾的是谷歌只能同时对比5个词条,超过5个会返回HTTP 403错误),这样读取出来的数据会是各个词条对比之后的相对热度数值。
再调用TrendReq().interest_over_time函数可以把词条的趋势数据输出为dataframe格式。
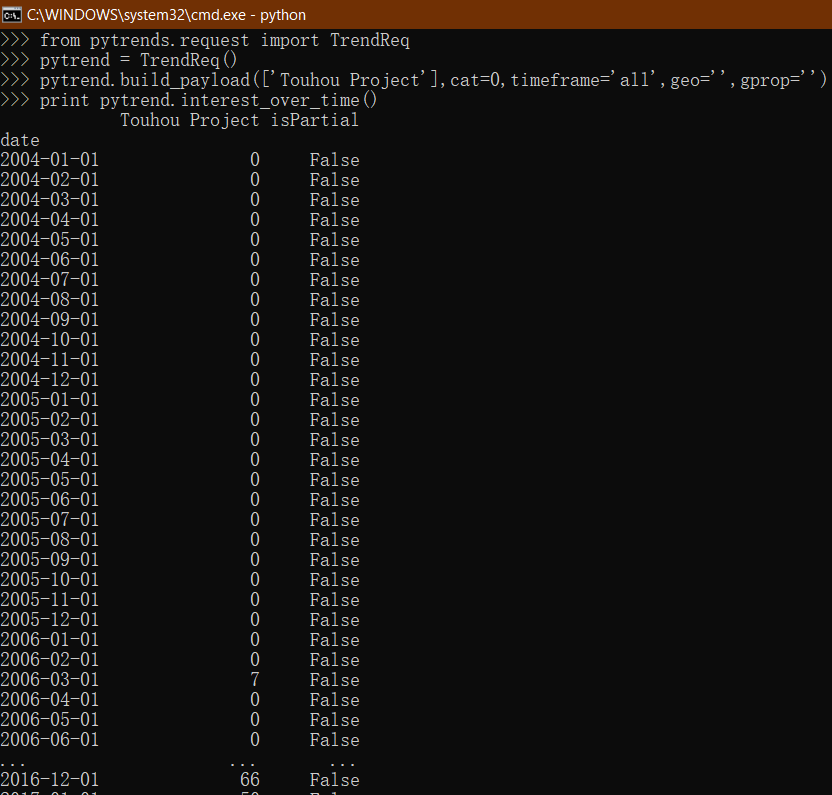
然后经过遍历输出到csv文件即可。
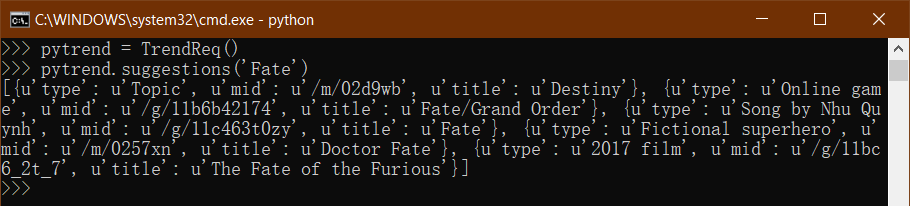
另外,谷歌趋势聚合了一些同主题的词条(把多个词条聚合到同一个词条当中),可以调用TrendReq().suggestions函数获取某词条对应的主题词条,这样可以减小单词条所带来的误差和漏算。这些主题词条对应的词条名称一般是一串代码。
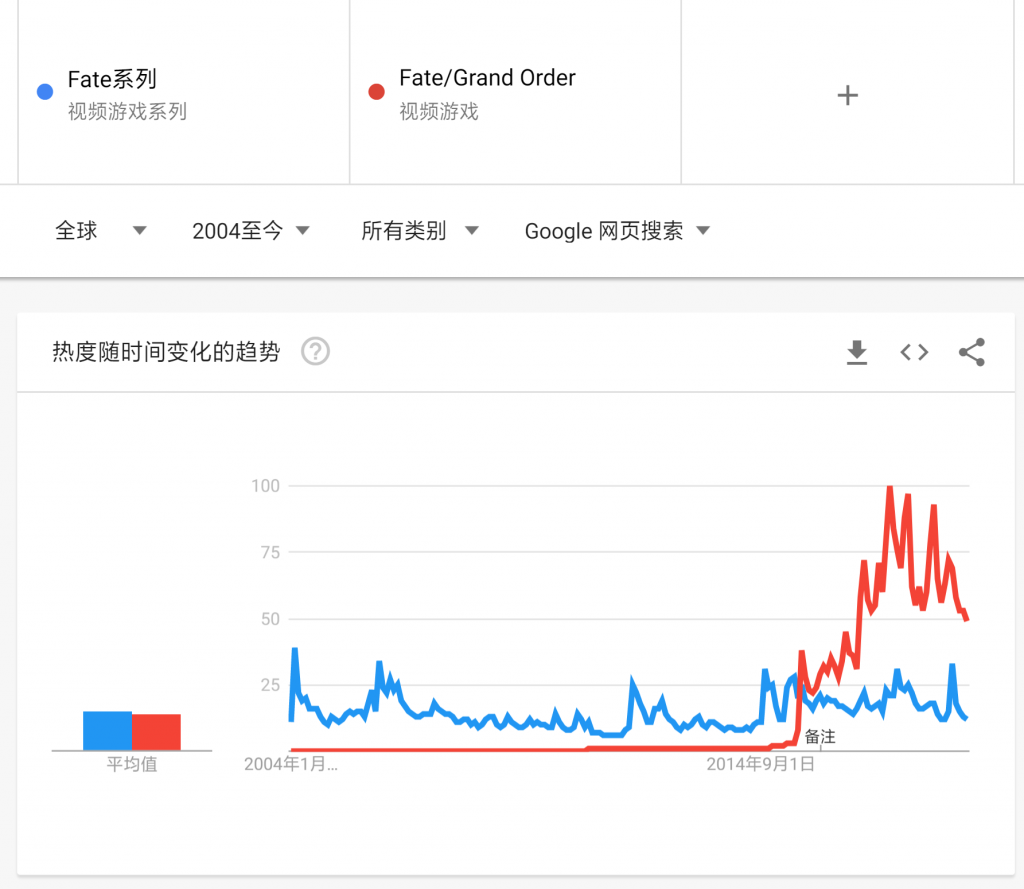
但也有一点问题,谷歌趋势有些主题所聚合的词条并不正确,例如主题词条“Fate系列”和词条“Fate/Grand Order”的热度趋势并不处于一个量级,很明显是谷歌的聚合算法有错误。
pytrends只能获取到谷歌趋势某段时间内的相对热度数值,并不能获取其绝对热度数值。因此在爬取数据的时候要设定好时间范围。
时间范围越大,所能获取到的热度数值范围反而越小。
如果从2004年开始获取至今的热度数据,时间单位是月而非天。
目前还没有办法获取从2004年至今每一天的热度数值,但能获取到从2004年至今每一天中的每小时的热度数值(热度有效范围仅限于当天)。
猜测谷歌并没有放出获取绝对热度数值的接口。
为了解决一次只能对5个词条对比来读取热度的问题,可以考虑先找到热度最大的那个词条,再用那个词条和其余的词条一一对比读取出对比后的热度。
由于相对热度的最大值为100,可能会对热度非常小的词条造成很大的误差。

0 条评论